Fully translated + good linking
This commit is contained in:
@@ -0,0 +1,147 @@
|
||||
---
|
||||
navigation: true
|
||||
title: Bash Scripts
|
||||
main:
|
||||
fluid: false
|
||||
---
|
||||
:ellipsis{left=0px width=40rem top=10rem blur=140px}
|
||||
# Bash Scripts
|
||||
|
||||
A few random scripts that saved my life.
|
||||
|
||||
## Detecting Duplicates and Replacing Them with Hardlinks
|
||||
---
|
||||
|
||||
Six months after downloading terabytes of media, I realized that Sonarr and Radarr were copying them into my Plex library instead of creating hardlinks. This happens due to a counterintuitive mechanism: if you mount multiple folders in Sonarr/Radarr, it sees them as different filesystems and thus cannot create hardlinks. That’s why you should mount only one parent folder containing all child folders (like `downloads`, `movies`, `tvseries` inside a `media` parent folder).
|
||||
|
||||
So I restructured my directories, manually updated every path in Qbittorrent, Plex, and others. The last challenge was finding a way to detect existing duplicates, delete them, and automatically create hardlinks instead—to save space.
|
||||
|
||||
My directory structure:
|
||||
|
||||
```console
|
||||
.
|
||||
└── media
|
||||
├── seedbox
|
||||
├── radarr
|
||||
│ └── tv-radarr
|
||||
├── movies
|
||||
└── tvseries
|
||||
```
|
||||
|
||||
The originals are in `seedbox` and must not be modified to keep seeding. The copies (duplicates) are in `movies` and `tvseries`. To complicate things, there are also unique originals in `movies` and `tvseries`. And within those, there can be subfolders, sub-subfolders, etc.
|
||||
|
||||
So the idea is to:
|
||||
|
||||
- list the originals in seedbox
|
||||
- list files in movies and tvseries
|
||||
- compare both lists and isolate duplicates
|
||||
- delete the duplicates
|
||||
- hardlink the originals to the deleted duplicate paths
|
||||
|
||||
Yes, I asked ChatGPT and Qwen3 (which I host on a dedicated AI machine). Naturally, they suggested tools like rfind, rdfind, dupes, rdupes, rmlint... But hashing 30TB of media would take days, so I gave up quickly.
|
||||
|
||||
In the end, I only needed to find `.mkv` files, and duplicates have the exact same name as the originals, which simplifies things a lot. A simple Bash script would do the job.
|
||||
|
||||
Spare you the endless Q&A with ChatGPT—I was disappointed. Qwen3 was much cleaner. ChatGPT kept pushing awk-based solutions, which fail on paths with spaces. With Qwen’s help and dropping awk, the results improved significantly.
|
||||
|
||||
To test, I first asked for a script that only lists and compares:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
# Create an associative array to store duplicates
|
||||
declare -A seen
|
||||
|
||||
# Find all .mkv files only (exclude directories)
|
||||
find /media/seedbox /media/movies /media/tvseries -type f -name "*.mkv" -print0 | \
|
||||
while IFS= read -r -d '' file; do
|
||||
# Get the file's inode and name
|
||||
inode=$(stat --format="%i" "$file")
|
||||
filename=$(basename "$file")
|
||||
|
||||
# If the filename has been seen before
|
||||
if [[ -n "${seen[$filename]}" ]]; then
|
||||
# Check if the inode is different from the previous one
|
||||
if [[ "${seen[$filename]}" != "$inode" ]]; then
|
||||
# Output the duplicates with full paths
|
||||
echo "Duplicates for \"$filename\":"
|
||||
echo "${seen["$filename"]} ${seen["$filename:full_path"]}"
|
||||
echo "$inode $file"
|
||||
echo
|
||||
fi
|
||||
else
|
||||
seen[$filename]="$inode"
|
||||
seen["$filename:full_path"]="$file"
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
This gave me outputs like:
|
||||
|
||||
```
|
||||
Duplicates for "episode1.mkv":
|
||||
1234567 /media/seedbox/sonarr/Serie 1/Season1/episode1.mkv
|
||||
2345678 /media/tvseries/Serie 1/Season1/episode1.mkv
|
||||
```
|
||||
|
||||
With `awk`, it would’ve stopped at `/media/seedbox/sonarr/Serie`. I’m far from an expert, but Qwen3 performed better and explained everything clearly.
|
||||
|
||||
Once I verified the output, I asked for a complete script: compare, delete duplicates, create hardlinks.
|
||||
|
||||
Again, ChatGPT disappointed. Despite my requests, it created hardlinks *before* deleting the duplicates—effectively linking and then deleting the link (though the original is kept). Not helpful.
|
||||
|
||||
Quick stopover to Qwen3, RTX 5090 in overdrive, and bam—much better result. Yes, it kept ChatGPT-style emojis, but here it is:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
echo "🔍 Step 1: Indexing original files in /media/seedbox..."
|
||||
declare -A seen
|
||||
|
||||
# Index all .mkv files in seedbox
|
||||
while IFS= read -r -d '' file; do
|
||||
filename=$(basename "$file")
|
||||
seen["$filename"]="$file"
|
||||
done < <(find /media/seedbox -type f -name "*.mkv" -print0)
|
||||
|
||||
echo "📦 Step 2: Automatically replacing duplicates..."
|
||||
total_doublons=0
|
||||
total_ko_saved=0
|
||||
|
||||
while IFS= read -r -d '' file; do
|
||||
filename=$(basename "$file")
|
||||
original="${seen[$filename]}"
|
||||
|
||||
if [[ -n "$original" && "$original" != "$file" ]]; then
|
||||
inode_orig=$(stat -c %i "$original")
|
||||
inode_dupe=$(stat -c %i "$file")
|
||||
|
||||
if [[ "$inode_orig" != "$inode_dupe" ]]; then
|
||||
size_kb=$(du -k "$file" | cut -f1)
|
||||
echo "🔁 Replacing:"
|
||||
echo " Duplicate : $file"
|
||||
echo " Original : $original"
|
||||
echo " Size : ${size_kb} KB"
|
||||
|
||||
rm "$file" && ln "$original" "$file" && echo "✅ Hardlink created."
|
||||
|
||||
total_doublons=$((total_doublons + 1))
|
||||
total_ko_saved=$((total_ko_saved + size_kb))
|
||||
fi
|
||||
fi
|
||||
done < <(find /media/movies /media/tvseries -type f -name "*.mkv" -print0)
|
||||
|
||||
echo ""
|
||||
echo "🧾 Summary:"
|
||||
echo " 🔗 Duplicates replaced by hardlink: $total_doublons"
|
||||
echo " 💾 Approx. disk space saved: ${total_ko_saved} KB (~$((total_ko_saved / 1024)) MB)"
|
||||
echo "✅ Done."
|
||||
```
|
||||
|
||||
So, in conclusion, I:
|
||||
- Learned many Bash subtleties
|
||||
- Learned never to blindly copy-paste a ChatGPT script without understanding and dry-running it
|
||||
- Learned that Qwen on a RTX 5090 is more coherent than ChatGPT-4o on server farms (not even mentioning “normal” ChatGPT)
|
||||
- Learned that even with 100TB of storage, monitoring it would’ve alerted me much earlier to the 12TB of duplicates lying around
|
||||
|
||||
Catch you next time for more exciting adventures.
|
||||
@@ -0,0 +1,67 @@
|
||||
---
|
||||
navigation: true
|
||||
title: Python Scripts
|
||||
main:
|
||||
fluid: false
|
||||
---
|
||||
:ellipsis{left=0px width=40rem top=10rem blur=140px}
|
||||
# Python Scripts
|
||||
|
||||
My messy Python creations
|
||||
|
||||
## 🤖 Nvidia Stock Bot
|
||||
---
|
||||
|
||||
For the past four years, the electronics hardware shortage has been relentless. Graphics cards are no exception. In 2020, I had to wait two months to get my RTX 3080. To manage it, I joined [JV Hardware](https://discord.gg/gxffg3GA96), where a small group of geeks had set up a bot that pinged users when GPUs became available.
|
||||
|
||||
Four years later and with 5,000 members on the server, the RTX 5000 series is being released. Yet, no working stock bot seems to exist. Not to mention a certain “influencer” who charges users for access to a bot that doesn’t even work. He manually copies alerts from other servers like ours, which have already solved the issue.
|
||||
|
||||
Anyway, eager to get an RTX 5090 for my AI-dedicated machine, I decided it was time to dive into Python—with a little help from ChatGPT. Along with another member, KevOut, who helped guide me through the APIs and initial architecture, I ended up building a clean and functional bot that sends different kinds of Discord alerts—all deployable in a simple Docker container.
|
||||
|
||||
After many setbacks, I went from this:
|
||||
|
||||
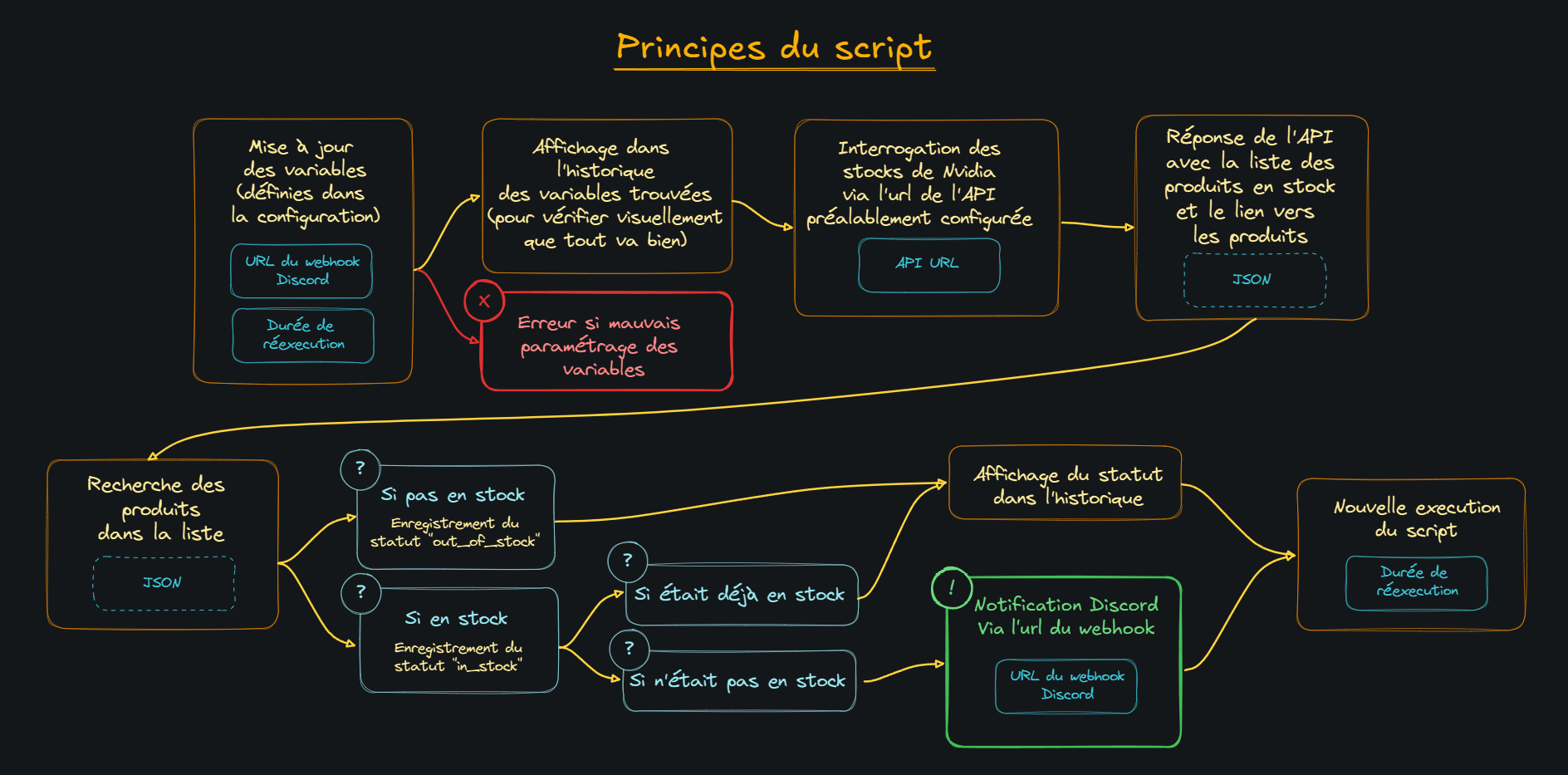
|
||||
|
||||
To this:
|
||||
|
||||
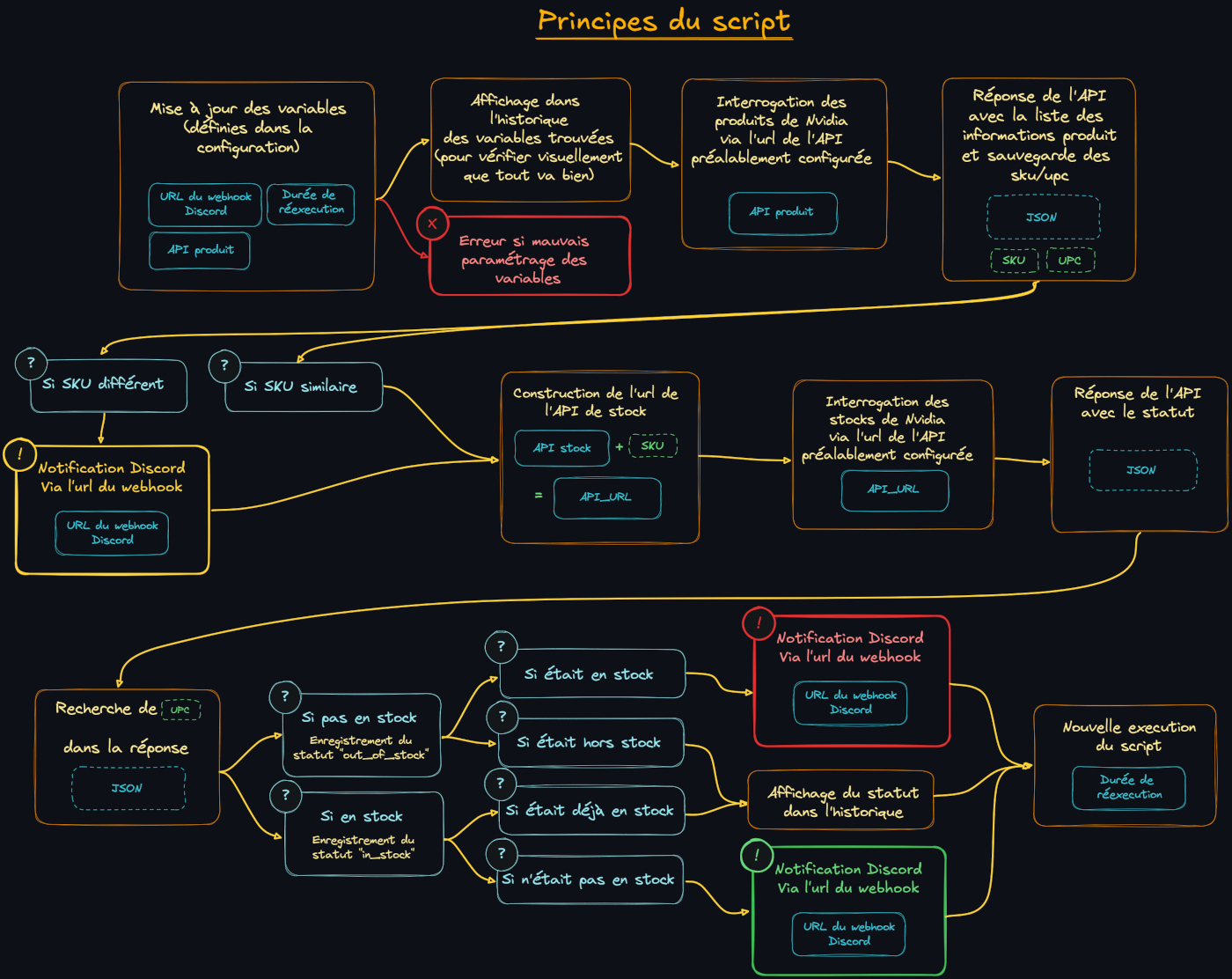
|
||||
|
||||
More info directly on the repo:
|
||||
|
||||
::card
|
||||
#title
|
||||
🐋 __Nvidia Stock Bot__
|
||||
#description
|
||||
[Nvidia GPU stock alert bot](https://git.djeex.fr/Djeex/nvidia-stock-bot)
|
||||
::
|
||||
|
||||
## 🤖 Adguard CIDRE Sync
|
||||
---
|
||||
|
||||
Adguard Home is a fantastic solution for DNS-level ad blocking and rewriting requests—perfect for removing ISP DNS trackers or intrusive ads.
|
||||
|
||||
It works great locally, but if you want all your devices (even on the go) to benefit, you’ll need to expose Adguard to the internet. Unfortunately, that means anyone can use it, potentially overloading your €1/month remote VPS.
|
||||
|
||||
Adguard allows whitelisting or blacklisting clients. The problem? To whitelist a client, you need their IP—but for mobile phones, that IP changes often. Instead of trying to whitelist ever-changing IPs, the better approach is to block broader IP ranges by region.
|
||||
|
||||
CIDRE is a tool that syncs geo-targeted IP ranges with firewalls. Instead of running CIDRE with a full firewall stack on the remote server, I figured I could just import those regularly updated IP ranges into Adguard’s blocklist.
|
||||
|
||||
Thus, Adguard CIDRE Sync was born: a container that syncs Adguard’s blocklist with CIDRE’s updated IP ranges on a schedule of your choosing.
|
||||
|
||||
The idea is to:
|
||||
- Backup Adguard’s config file on first run (original untouched version saved)
|
||||
- Download selected country IP ranges via an environment variable
|
||||
- Let you manually add custom IPs via a file
|
||||
- Concatenate, backup the config again (as the updated version), and inject the list into the correct blocklist section
|
||||
- Reload Adguard by restarting the container (using Docker socket proxy for limited permissions)
|
||||
|
||||
All fully autonomous, with frequency set via environment variable in the `docker-compose` config.
|
||||
|
||||
More info directly on the repo:
|
||||
|
||||
::card
|
||||
#title
|
||||
🐋 __Adguard CIDRE Sync__
|
||||
#description
|
||||
[Adguard blocklist sync bot](https://git.djeex.fr/Djeex/adguard-cidre)
|
||||
::
|
||||
@@ -0,0 +1,2 @@
|
||||
icon: noto:test-tube
|
||||
navigation.title: My nonsense
|
||||
Reference in New Issue
Block a user