First commit -clean
This commit is contained in:
@@ -0,0 +1,146 @@
|
||||
---
|
||||
navigation: true
|
||||
title: Scripts bash
|
||||
main:
|
||||
fluid: false
|
||||
---
|
||||
:ellipsis{left=0px width=40rem top=10rem blur=140px}
|
||||
# Scripts bash
|
||||
|
||||
Quelques scripts en vracs qui m'ont sauvé la vie.
|
||||
|
||||
## Detection de doublons et remplacement par des hardlinks
|
||||
---
|
||||
|
||||
Six mois après avoir téléchargé des térabytes de media, je me suis rendu compte que Sonarr et Radarr les copaient dans ma biblio Plex au lieu de créer des hardlinks. C'est dû à un mécanisme contre intuitif qui est que si vous montez plusieurs dossiers dans Sonarr/Radarr, il les voit comme deux systemes de fichiers différents. Et ne peut donc pas créer de hardlinks. C'est pour cela qu'il ne faut monter qu'un seul dossier parent, qui contient tous les enfants (`downloads`, `movies`, `tvseries` dans le dossier parent `media` par exemple).
|
||||
|
||||
J'ai donc restructuré mes dossiers, remis à la main chaque chemin dans Qbittorrent, Plex, et autres. Il restait à trouver un moyen de détecter les doublons existants et d'automatiquement les supprimer et de créer des hardlinks à la place, pour économiser de l'espace.
|
||||
|
||||
Mes dossiers :
|
||||
|
||||
```console
|
||||
.
|
||||
└── media
|
||||
├── seedbox
|
||||
├── radarr
|
||||
│ └── tv-radarr
|
||||
├── movies
|
||||
└── tvseries
|
||||
```
|
||||
|
||||
Mes dossiers originaux sont dans `seedbox`, et il ne faut surtout pas les modifier pour qu'ils continuent d'etre "seed". Les copies, et donc doublons, sont dans `movies` et `tvseries`. Mais pour complexifier la chose, j'ai aussi des media uniques originaux déposés par ailleurs dans `movies` et `tvseries`, sinon cela serait trop facile. Et dans ces deux dossiers, il peut y avoir des sous dossiers, des sous-sous dossiers, etc.
|
||||
|
||||
L'idée est donc de :
|
||||
|
||||
- lister les originaux dans seedbox
|
||||
- lister les fichiers dans movies
|
||||
- comparer les deux listes et isoler les chemins des doublons
|
||||
- supprimer les doublons
|
||||
- hardlinker les originaux dans les dossiers des doublons supprimés
|
||||
|
||||
Alors oui j'ai demandé à ChatGPT et à Qwen3 (que j'héberge sur une machine dédiée à l'IA). Et evidemment ils m'ont conseillé les rfind, rdfind, dupes, rdupes, rmlint... Mais comparer les hash de 30TB de media, faudrait plusieurs jours, j'ai vite abandonné.
|
||||
|
||||
Au final, je n'ai que des `.mkv` à chercher et les doublons ont exactement les mêmes noms que les originaux, ce qui simplifie grandement la tâche. Un simple script bash devait donc être suffisant.
|
||||
|
||||
Je vous passe les incessantes questions réponses avec ChatGPT, je suis assez déçu. Qwen3 a été bien plus propre. ChatGPT n'a pas cessé de mettre des solutions type awk, qui pètent la lecture des chemins au moindre espace. En faisant relire à Qwen, et en lui demandant de se passer de awk, le résultat a été immediatement plus qualitatif.
|
||||
|
||||
Pour tester, j'ai d'abord demandé un script qui ne fait que lister et comparer :
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
# Créer un tableau associatif pour stocker les doublons
|
||||
declare -A seen
|
||||
|
||||
# Trouver tous les fichiers .mkv uniquement (exclure les dossiers)
|
||||
find /media/seedbox /media/movies /media/tvseries -type f -name "*.mkv" -print0 | \
|
||||
while IFS= read -r -d '' file; do
|
||||
# Obtenir l'inode du fichier et son chemin
|
||||
inode=$(stat --format="%i" "$file")
|
||||
filename=$(basename "$file")
|
||||
|
||||
# Si ce nom de fichier a déjà été vu
|
||||
if [[ -n "${seen[$filename]}" ]]; then
|
||||
# Vérifier si l'inode est différent du précédent
|
||||
if [[ "${seen[$filename]}" != "$inode" ]]; then
|
||||
# Ajouter le doublon à la sortie en affichant les chemins complets
|
||||
echo "Doublons pour \"$filename\" :"
|
||||
echo "${seen["$filename"]} ${seen["$filename:full_path"]}"
|
||||
echo "$inode $file"
|
||||
echo
|
||||
fi
|
||||
else
|
||||
# Si c'est la première fois qu'on rencontre ce nom de fichier
|
||||
seen[$filename]="$inode"
|
||||
seen["$filename:full_path"]="$file"
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
J'ai ainsi obtenu ce type de réponse :
|
||||
|
||||
```
|
||||
Doublons pour "episode1.mkv" :
|
||||
1234567 /media/seedbox/sonarr/Serie 1/Season1/episode1.mkv
|
||||
2345678 /media/tvseries/Serie 1/Season1/episode1.mkv
|
||||
```
|
||||
|
||||
Avec "awk", il se serait arrêté à `/media/seedbox/sonarr/Serie`. Je ne suis absolument pas un pro, mais Qwen3 a été plus performant et m'a expliqué de A à Z pourquoi et comment faire.
|
||||
|
||||
Une fois que j'ai vu que cela fonctionnait bien, j'ai demandé un script qui fait l'intégralité de la cinématique, de la comparaison aux hardlinks en passant par la suppression des doublons.
|
||||
Encore une fois ChatGPT a été décevant. Malgré mes demandes, il créait d'abord les hardlinks et ensuite il supprimait les doublons. Ce qui.. suprimme aussi le lien (meme si cela conserve l'originale). Idiot.
|
||||
Petit détour par Qwen3, et ma RTX 5090 en PLS, et paf un résultat bien plus propre. Bon il a gardé les emoji de ChatGPT qui peut pas s'empecher d'en mettre partout, mais voilà :
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
echo "🔍 Étape 1 : Indexation des fichiers originaux dans /media/seedbox..."
|
||||
declare -A seen
|
||||
|
||||
# Indexe tous les .mkv dans seedbox
|
||||
while IFS= read -r -d '' file; do
|
||||
filename=$(basename "$file")
|
||||
seen["$filename"]="$file"
|
||||
done < <(find /media/seedbox -type f -name "*.mkv" -print0)
|
||||
|
||||
echo "📦 Étape 2 : Remplacement automatique des doublons..."
|
||||
total_doublons=0
|
||||
total_ko_economises=0
|
||||
|
||||
while IFS= read -r -d '' file; do
|
||||
filename=$(basename "$file")
|
||||
original="${seen[$filename]}"
|
||||
|
||||
if [[ -n "$original" && "$original" != "$file" ]]; then
|
||||
inode_orig=$(stat -c %i "$original")
|
||||
inode_dupe=$(stat -c %i "$file")
|
||||
|
||||
if [[ "$inode_orig" != "$inode_dupe" ]]; then
|
||||
size_kb=$(du -k "$file" | cut -f1)
|
||||
echo "🔁 Remplacement :"
|
||||
echo " Doublon : $file"
|
||||
echo " Original : $original"
|
||||
echo " Taille : ${size_kb} Ko"
|
||||
|
||||
rm "$file" && ln "$original" "$file" && echo "✅ Hardlink créé."
|
||||
|
||||
total_doublons=$((total_doublons + 1))
|
||||
total_ko_economises=$((total_ko_economises + size_kb))
|
||||
fi
|
||||
fi
|
||||
done < <(find /media/movies /media/tvseries -type f -name "*.mkv" -print0)
|
||||
|
||||
echo ""
|
||||
echo "🧾 Résumé :"
|
||||
echo " 🔗 Doublons remplacés par hardlink : $total_doublons"
|
||||
echo " 💾 Espace disque économisé approximatif : ${total_ko_economises} Ko (~$((total_ko_economises / 1024)) Mo)"
|
||||
echo "✅ Terminé."
|
||||
```
|
||||
|
||||
Bilan j'ai :
|
||||
- appris pas mal de subtilité bash
|
||||
- appris qu'il ne faut jamais copier coller un script généré ChatGPT sans le comprendre et sans le tester en dry-run
|
||||
- appris que Qwen sur une RTX 5090 est plus cohérent que ChatGPT 4o sur des fermes de serveurs (je vous passe les résultats de la version "normale").
|
||||
- appris que même quand on a 100TB d'espace, monitorer ce dernier m'aurait permis de voir beaucoup plus tot que j'avais 12TB de doublons qui trainent.
|
||||
|
||||
A plus tard pour de nouvelles aventures passionnantes.
|
||||
@@ -0,0 +1,69 @@
|
||||
---
|
||||
navigation: true
|
||||
title: Scripts python
|
||||
main:
|
||||
fluid: false
|
||||
---
|
||||
:ellipsis{left=0px width=40rem top=10rem blur=140px}
|
||||
# Scripts python
|
||||
|
||||
Mes cochonneries en python
|
||||
|
||||
## 🤖 Nvidia Stock Bot
|
||||
---
|
||||
|
||||
Depuis déjà 4 ans, la pénurie de materiel electronique fait rage. Et les cartes graphiques ne sont pas épargnées. En 2020, j'ai du attendre 2 mois pour obtenir mon exemplaire de RTX 3080, et pour cela j'ai du m'inscrire sur [JV Hardware](https://discord.gg/gxffg3GA96) où une poignée de geek avait mis en place un bot qui envoyait un ping lorsqu'elles étaient disponibles.
|
||||
|
||||
4 ans après et 5000 abonnés plus tard, vient la sortie des RTX 5000. Et là aucun bot dispo sur le marché ne semble fonctionner correctement. Je ne parle même pas d'un certain "influenceur" qui se permet de faire payer l'accès à son bot qui ne fonctionne meme pas. Il copie à la main les alertes provenant d'autres serveurs, comme le notre qui ont résolu le problème.
|
||||
|
||||
Quoiqu'il en soit, désireux d'obtenir une RTX 5090 pour ma machine dédiée à l'IA, je me suis dit qu'il était peut etre le temps de plonger dans le monde de python et de ChatGPT pour m'épauler. A l'aide d'un autre membre du serveur, KevOut, qui a principalement guidé sur le principe de départ et les sources des différentes API, j'ai réussi à obtenir un bot propre, fonctionnel, qui envoie différents types d'alertes via Discord. Avec un simple conteneur docker à déployer.
|
||||
|
||||
Après moult déconvenues, je suis passé de ceci :
|
||||
|
||||
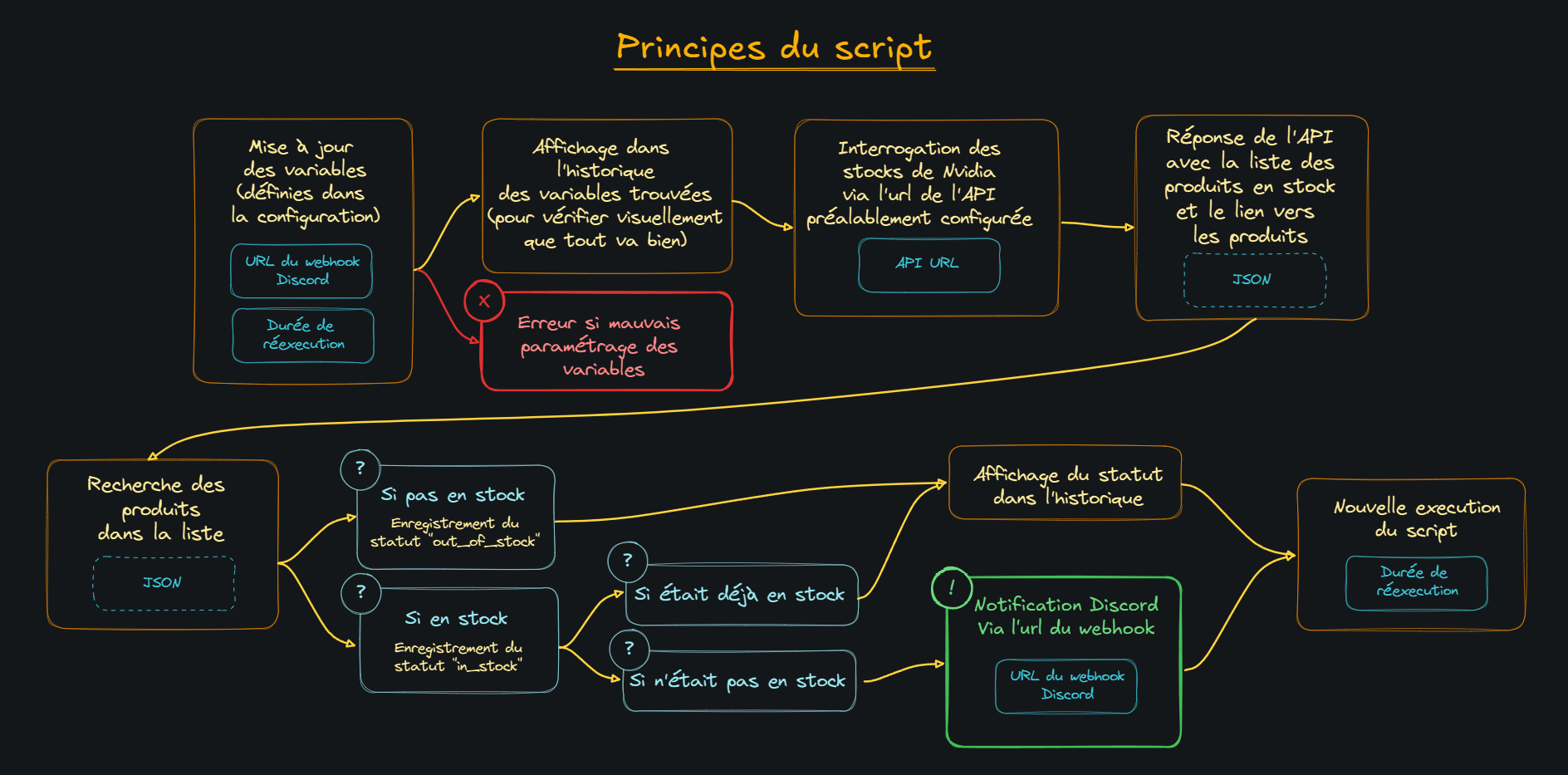
|
||||
|
||||
à cela :
|
||||
|
||||
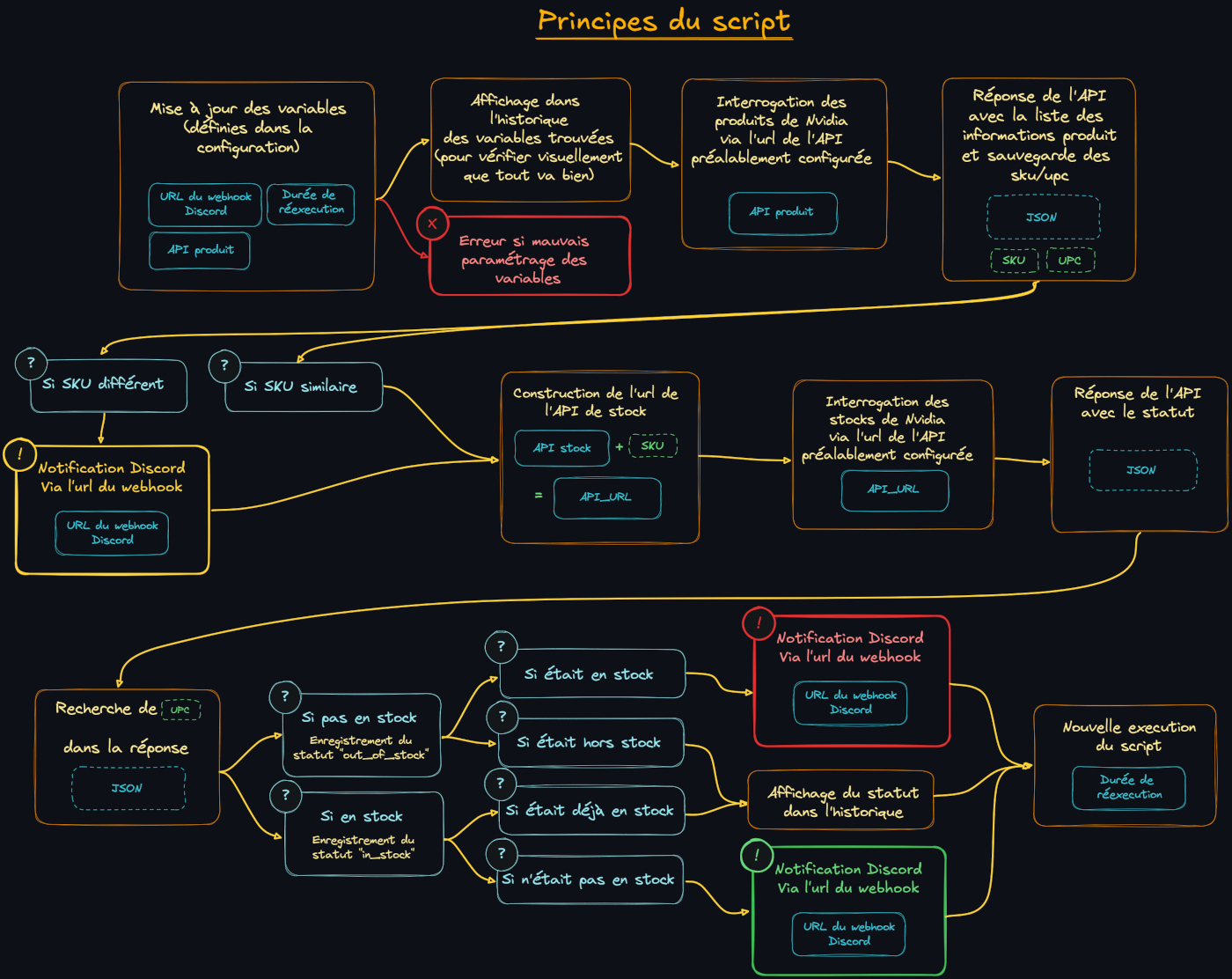
|
||||
|
||||
Plus d'infos directement sur le repo :
|
||||
|
||||
|
||||
::card
|
||||
#title
|
||||
🐋 __Nvidia Stock Bot__
|
||||
#description
|
||||
[Robot d'alerte de stock de GPU Nvidia](https://git.djeex.fr/Djeex/nvidia-stock-bot)
|
||||
::
|
||||
|
||||
## 🤖 Adguard CIDRE Sync
|
||||
---
|
||||
|
||||
Adguard Home est une solution merveilleuse pour filter ses requêtes DNS et ainsi se débarasser de la publicité ou des DNS des fournisseurs d'accès, ou encore réécrire des requetes.
|
||||
|
||||
Quand c'est en local, c'est très chouette. Mais quand on veut que tout ses appareils en profitent même à l'exterieur, on est obligé de l'exposer sur le net. Et n'importe qui peut s'en servir et saturer le petit remote à 1€ qu'on a pris pour l'heberger.
|
||||
|
||||
Adguard permet d'avoir des listes de clients autorisés ou bloqués. Problème, pour autoriser un client il faut son IP, et dans le cas d'un téléphone sur le réseau mobile, beh elle change régulièrement. L'idée est donc plutot de bloquer des listes générales plutot que d'autoriser des IP qui de toute façon changent régulièrement.
|
||||
|
||||
CIDRE est un outil qui permet de synchroniser des listes de plages IP géolocalisées mises à jour régulièrement avec un pare feu. Plutot que de faire tourner CIDRE sur le remote complet avec des règles de pare feu complexes, je me suis dit qu'il fallait simplement s'arranger pour ajouter les plages IP à jour que CIDRE propose au systeme de block list d'adguard, selon les pays que l'on souhaite bloquer.
|
||||
|
||||
C'est ainsi qu'est né Adguard CIDRE Sync, un conteneur qui synchronise régulièrement la block list d'Adguard avec les plages IP recensées par CIDRE à la fréquence que vous voulez.
|
||||
|
||||
L'idée etant de :
|
||||
- Backup le fichier de conf d'Adguard au premier lancement (le fichier jamais touché par le robot est ainsi conservé au cas où)
|
||||
- Télécharger la liste des pays selectionnés via une variable d'environnement
|
||||
- Permettre d'ajouter soi-meme des IP "à la main" dans un fichier
|
||||
- Concaténer le tout, backup le fichier de conf (dernière update), et injecter la liste dans la bonne section du fichier de conf d'Adguard
|
||||
- Recharger Adguard en relançant le container (accès au socket via docker socket proxy pour limiter les permissions)
|
||||
|
||||
Tout ceci de manière complètement autonome, avec une fréquence choisie en variable d'environnement dans la conf du compose.
|
||||
|
||||
Plus d'infos directement sur le repo :
|
||||
|
||||
|
||||
::card
|
||||
#title
|
||||
🐋 __Adguard CIDRE Sync__
|
||||
#description
|
||||
[Robot de synchronisation de la blocklist d'Adguard](https://git.djeex.fr/Djeex/adguard-cidre)
|
||||
::
|
||||
@@ -0,0 +1,2 @@
|
||||
icon: noto:test-tube
|
||||
navigation.title: Mes bêtises
|
||||
Reference in New Issue
Block a user